react 组件进阶之 Portals
本文共 808 字,大约阅读时间需要 2 分钟。
含义
Portals 翻译为门户,但是感觉不对。作用类似插槽,但是不是vue 里面的插槽哦,有点像vue3 里面的
teleport,两者的作用都是将对于的虚拟dom 插入到真实dom的某个位置上。这里不讲两者的区别,只讲 Portals 的用法
语法
ReactDOM.createPortal(child, container)
第一个参数(child)是任何可渲染的 React 子元素,例如一个元素,字符串或 fragment。第二个参数(container)是一个 DOM 元素。
用法
import React, { PureComponent } from 'react'import ReactDOM from 'react-dom'function CompB() { return ( 我是子组件B )}function CompA() { return ReactDOM.createPortal( ( 我是子组件A 效果
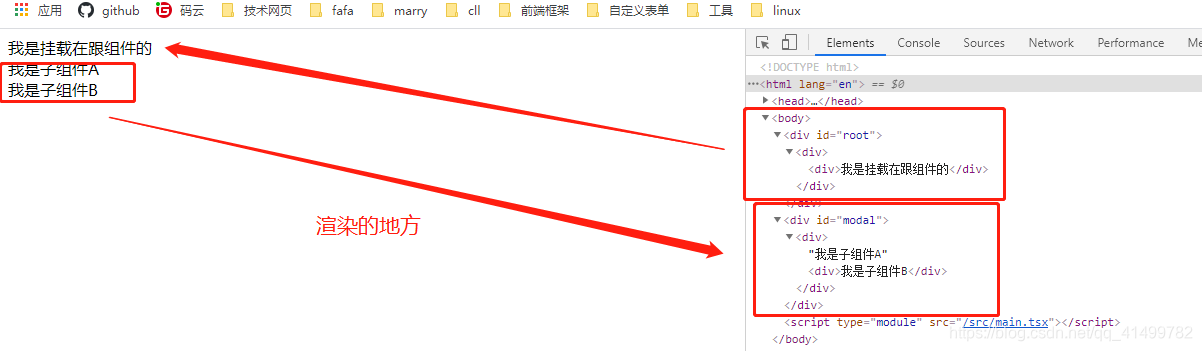
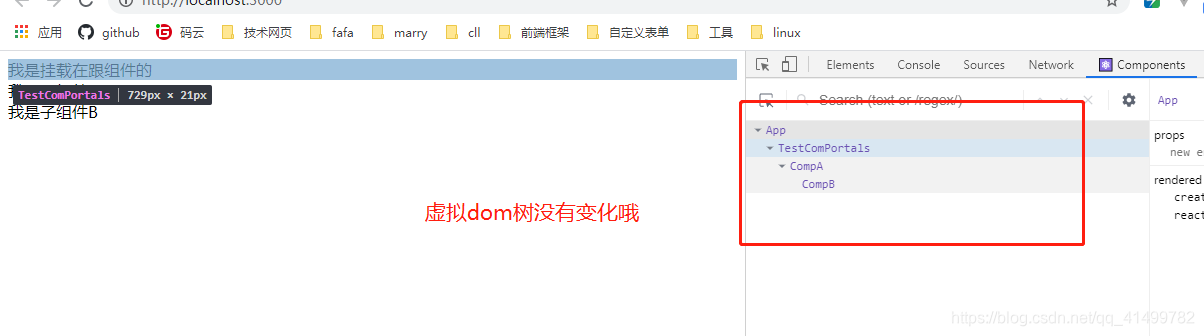
使用注意:
- 使用 Portals 改变的是真实dom结构,虚拟的dom 树是不会有变化的
- 注意改变的
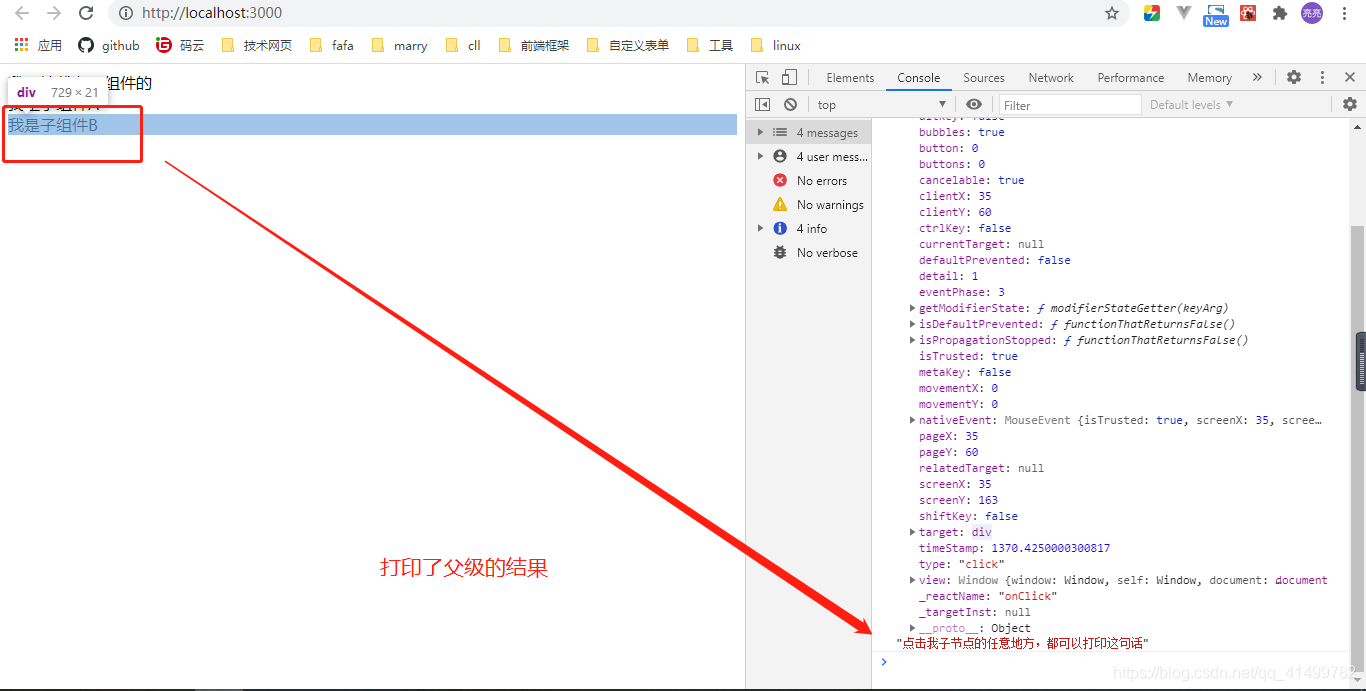
事件冒泡, 由于react 中的事件是由react 包装过后的,所以他的真实事件冒泡是通过虚拟的dom 树里面来进行冒泡的。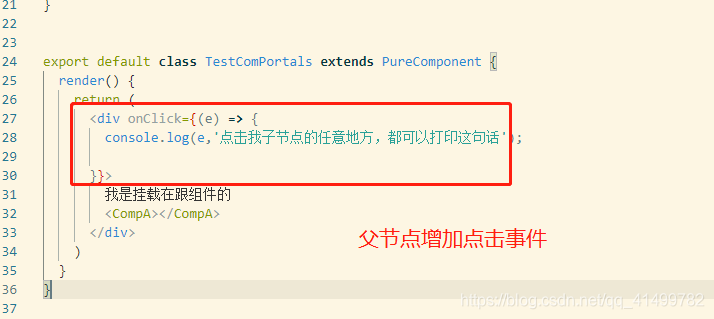
效果
转载地址:http://qfjhz.baihongyu.com/
你可能感兴趣的文章
MySQL 数据库操作指南:学习如何使用 Python 进行增删改查操作
查看>>
MySQL 数据库的高可用性分析
查看>>
MySQL 数据库设计总结
查看>>
Mysql 数据库重置ID排序
查看>>
Mysql 数据类型一日期
查看>>
MySQL 数据类型和属性
查看>>
mysql 敲错命令 想取消怎么办?
查看>>
Mysql 整形列的字节与存储范围
查看>>
mysql 断电数据损坏,无法启动
查看>>
MySQL 日期时间类型的选择
查看>>
Mysql 时间操作(当天,昨天,7天,30天,半年,全年,季度)
查看>>
MySQL 是如何加锁的?
查看>>
MySQL 是怎样运行的 - InnoDB数据页结构
查看>>
mysql 更新子表_mysql 在update中实现子查询的方式
查看>>
MySQL 有什么优点?
查看>>
mysql 权限整理记录
查看>>
mysql 权限登录问题:ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)
查看>>
MYSQL 查看最大连接数和修改最大连接数
查看>>
MySQL 查看有哪些表
查看>>
mysql 查看锁_阿里/美团/字节面试官必问的Mysql锁机制,你真的明白吗
查看>>